
Can an LLM Curate My News Feed?

Intro
In my previous post I discussed building a personal knowledge management system. One of the key aspects of collecting relevant and new information is scanning news aggregators like Hacker News and Reddit for new posts of interests.
I know the types of articles I like and can scan for them relatively easily, but wouldn’t it be nice if I was only presented with the articles that meet some sort of threshold of relevancy to my interests? Maybe articles of 0% match are completely against my interests and 100% would be a perfect match, and I only want to see those that are above 75%.
For example:
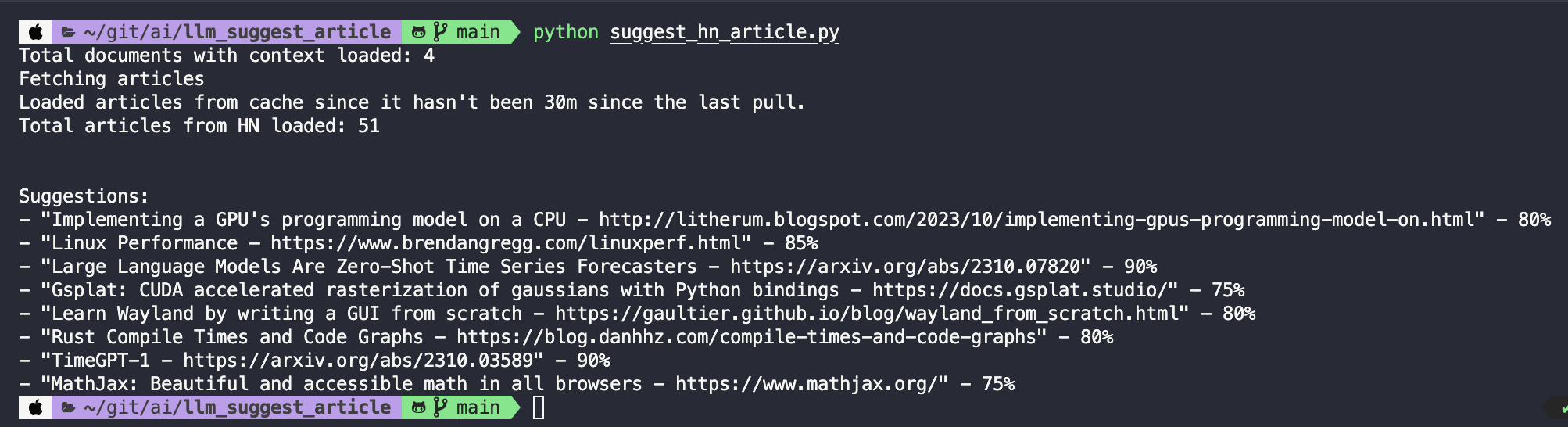
Let’s build it using Python, LangChain, and GPT!
Git Repo
Find all examples here: https://github.com/hortonew/llm_suggest_article.
Examples to find a new programming language to learn
Barebones Example
This is the barebones example of using LangChain and hitting the OpenAI API, using the GPT-4 LLM to get an answer to a question.
The full example project later in the post will go through the setup steps to do something like this, adding your API key and installing other dependencies. The examples here are to give you a taste of what’s to come.
Example Code
|
|
Because this is generic to everyone on the planet, my response might look like:
If you enjoy Python, you might find these languages enjoyable to learn:
1. Ruby: Like Python, Ruby is designed to be easy to read and write. It's very high-level, which means it abstracts away most of the complex details of the machine. Ruby is also used widely in web development with the Ruby on Rails framework.
2. Swift: If you're interested in mobile app development, especially for iOS, Swift might be a fun choice. It was developed by Apple to replace Objective-C, and it's more streamlined and safer.
3. Go: Developed by Google, Go (also known as Golang) is designed to be simple and efficient, much like Python. It's gaining popularity for web servers and data science applications.
4. JavaScript: If you're interested in web development, JavaScript is a must. It's the scripting language of the web, and with the rise of Node.js, it's now used on the server side as well.
5. Kotlin: If you're interested in Android app development, Kotlin is a great language to learn. It's officially supported by Google for Android development, and it's more modern and concise than Java.
6. Rust: If you're interested in system programming or game development, Rust is a good choice. It's designed to be safe, concurrent, and practical. It's a bit more complex than Python, but it's very powerful and its community values thorough documentation, which can make it fun to learn.
Remember, the best programming language to learn is often determined by what you want to do with it, so it's good to have a project or goal in mind as you learn.
Example using your context in your queries
Next we switch over to using a ConversationalRetrievalChain which lets us use a custom retriever (our in-memory vector store). This vector store is comprised of data loaded from the data/ directory using the DirectoryLoader. All of that context will be used in our next query, and the context consists of files that describe me and my interests. In one of the text files I actually call out - I like languages like: Python, Rust, Go.
This is the difference between the LLM suggesting what might be useful to anyone, generically, to what will be useful to you (considering your interests).
Example Code
|
|
My response now looks like:
As per the provided context, the person enjoys programming in Python, Rust, and Go.
These could potentially be fun languages to learn if you like Python.
That’s all well and good, but we want to use this to pick out interesting Hacker News articles. Let’s code that up.
Curating your feed
The Structure
We’re going to need a few things:
- An OpenAI API key. Yes, this costs money (but probably $0.20 for what we’re about to try)
- A directory that is a database of what we like. A bio, our interests, things we don’t like, etc.
- Code to pull the titles and URLs of a news feed (e.g. https://news.ycombinator.com/)
- Code to vectorize our personal interest database and to query GPT-4 with that context.
Create a directory with the following structure. The names don’t matter, so organize them as you see fit.
data/
bio.txt
articles_ive_liked.txt
my_interests.txt
hn_articles.py
requirements.txt
suggest_hn_article.py
You’ll notice I have a few text documents that are relevant to me. You should have something similar. Play around with the structure and compare outputs when you change the structure up.
In bio.txt I just give an elevator pitch for who I am. Feel free to go as deep as you want and play around with how it affects your results. For example:
I'm a python developer, AWS cloud architect, devops professional, and site reliability engineer.
I'm learning to be a better blogger, love productivity and efficiency hacks, and read a lot of books.
In articles_ive_liked.txt I start taking the responses from this application and figuring out if they fit my interests or not. This is probably not necessary but I’m trying to have an accurate picture of what I like for future iterations. For example:
This is a list of articles that fit my interests:
- I liked: TimeGPT-1 - https://arxiv.org/abs/2310.03589
- I liked: What I wish I knew when I got my ASN - https://quantum5.ca/2023/10/10/what-i-wish-i-knew-when-i-got-my-asn/
- I liked: Removal of Mazda Connected Services integration - https://www.home-assistant.io/blog/2023/10/13/removal-of-mazda-connected-services-integration/
- I liked: You are onboarding developers wrong (Featuring Ambient Game Engine) - https://dickymirrors.substack.com/p/you-are-onboarding-developers-wrong
I did not enjoy these articles:
- I did not like: Making Rust supply chain attacks harder with Cackle-https://davidlattimore.github.io/making-supply-chain-attacks-harder.html
- I did not like: Making GRID's spreadsheet engine 10% faster-https://alexharri.com/blog/grid-engine-performance
- I did not like: Takeaways from hundreds of LLM finetuning experiments with LoRA-https://lightning.ai/pages/community/lora-insights/
Lastly, in my_interests.txt I just list out other interests as a bulleted list. Remember, these are things you want to steer your blog post suggestions around.
- You may really enjoy something in your dislike section, you just might not want to get suggested posts around it.
- You may know nothing about something in your interests section and want to start seeing more posts about it.
For example:
A list of my interests are:
- I like languages like: Python, Rust, Go
- I like Docker and Kubernetes
- I like AWS
- I like Piano
- I like Music Theory, Graph Theory, Network Theory
- I like Network Engineering
- I like Home Assistant, Plex, Tailscale
- I like Video games and Steam
- I like Android, Mac OSX
Things I don't care about or just don't want to read about:
- I don't like languages like Javascript, Java, Visual Basic
- I don't like HTML/CSS
- I don't like Articles before the current year
- I don't like iPhone, iPad
- I don't like Azure, Google Cloud
- I don't like Cars
The Code
Python dependencies
# requirements.txt
bs4
chromadb
keyring
langchain
openai
requests
tiktoken
unstructured
Install the dependencies
python3.11 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt
hn_articles.py
The purpose of this file is to pull down Hacker News articles (posts), grabbing the title and URL of the first couple pages. It will cache these articles for 30m, so it won’t reach back out over the internet if the cached values are less than 30min old.
|
|
suggest_hn_article.py
This is the entrypoint that invokes hn_articles to get content and runs it and your context through the LLM.
|
|
Output
Here’s my curated feed with percentages for how relevant they are to me. I’ll only see items that are 75% relevant or higher.
Day 1
- "Implementing a GPU's programming model on a CPU - http://litherum.blogspot.com/2023/10/implementing-gpus-programming-model-on.html" - 80%
- "Linux Performance - https://www.brendangregg.com/linuxperf.html" - 85%
- "Fcron Is the Best Cron - https://dbohdan.com/fcron" - 75%
- "Large Language Models Are Zero-Shot Time Series Forecasters - https://arxiv.org/abs/2310.07820" - 80%
- "Gsplat: CUDA accelerated rasterization of gaussians with Python bindings - https://docs.gsplat.studio/" - 80%
- "Multi-modal prompt injection image attacks against GPT-4V - https://simonwillison.net/2023/Oct/14/multi-modal-prompt-injection/" - 85%
- "Rust Compile Times and Code Graphs - https://blog.danhhz.com/compile-times-and-code-graphs" - 75%
- "TimeGPT-1 - https://arxiv.org/abs/2310.03589" - 80%
Day 2
- "Hacker News" for retro computing and gaming - https://blog.jgc.org/2023/10/hacker-news-for-retro-computing-and.html - 80%
- Cloudflare Sippy: Incrementally Migrate Data from AWS S3 to Reduce Egress Fees - https://www.infoq.com/news/2023/10/cloudflare-sippy-migrate-s3/ - 90%
- Transactions and Concurrency in PostgreSQL - https://doadm-notes.blogspot.com/2023/10/transactions-and-concurrency-in.html - 75%
- Implementing a GPU's programming model on a CPU - http://litherum.blogspot.com/2023/10/implementing-gpus-programming-model-on.html - 80%
- Nvidia, one of tech's hottest companies, is fine with remote work - https://fortune.com/2023/10/14/nvidia-skips-return-to-office-sticks-to-remote-work-among-hottest-tech-companies/ - 75%
- Linux on an 8bit Microcontroller - https://dmitry.gr/?r=05.Projects&proj=07.%20Linux%20on%208bit - 80%
- Large Language Models Are Zero-Shot Time Series Forecasters - https://arxiv.org/abs/2310.07820 - 85%
The output still isn’t what I would call perfect, but I will continue to tune my context with more examples of what articles I do or don’t like.
Where to go from here
Find other places where you might have context to add. You’ll need to tweak the search_kwargs you use in your ConversationalRetrievalChain.
Experiment with other loaders
- You can can pull in PDFs (
pip install unstructured[pdf]) - It’s possible to pull in Obsidian files using the ObsidianLoader
- Add context using loaders for 3rd party APIs like Confluence, AWS S3, or Discord.
Curate content from other sources
- Other social news sources like Reddit, Pinterest, or Slashdot
- Traditional news sources
- Pull in recipes you might like from sites like Tasty or Serious Eats
Add a front end
Build a front end using an API, GUI, or TUI to start this script up. Some options include:
Use a persistent vector database
There are many options for vector store integrations, but one easy one to run locally is to use ChromaDB. You can modify the code like the following to use a directory called persist to store the vectors.
From:
index = VectorstoreIndexCreator().from_loaders(loaders)
To:
# ...
from langchain.vectorstores import Chroma
# ...
if os.path.exists("persist"):
vectorstore = Chroma(persist_directory="persist", embedding_function=OpenAIEmbeddings())
index = VectorStoreIndexWrapper(vectorstore=vectorstore)
else:
index = VectorstoreIndexCreator(vectorstore_kwargs={"persist_directory":"persist"}).from_loaders([loader])
# ...